



Distribuição de filas e atribuição de atendentes no Blip: como evitar falhas críticas e garantir eficiência no atendimento
Uma distribuição de tickets mal configurada pode comprometer totalmente a operação de atendimento de uma empresa. Quando chats não são atribuídos corretamente a filas ou atendentes, o tempo de resposta aumenta, o cliente se frustra e a equipe perde eficiência. Mais do que um problema técnico, isso representa um risco direto à reputação e à produtividade da operação.
📖Neste guia, você vai entender como o sistema de filas e atribuição do Blip funciona, identificar as causas mais comuns de falhas e, principalmente, aprender como evitar esses problemas com ações práticas, padronizadas e inteligentes:
Compreendendo o motor de distribuição de tickets no Blip
Antes de pensar em resolver falhas, é fundamental entender como o sistema de distribuição do Blip realmente funciona.
Em resumo, o processo é dividido em três etapas principais:
- Roteamento do ticket para a fila correta, com base em regras personalizadas;
- Verificação da disponibilidade de atendentes dentro da fila;
- Atribuição automática do ticket ao atendente mais adequado, de acordo com o modo de distribuição configurado.
Modos de distribuição disponíveis no Blip
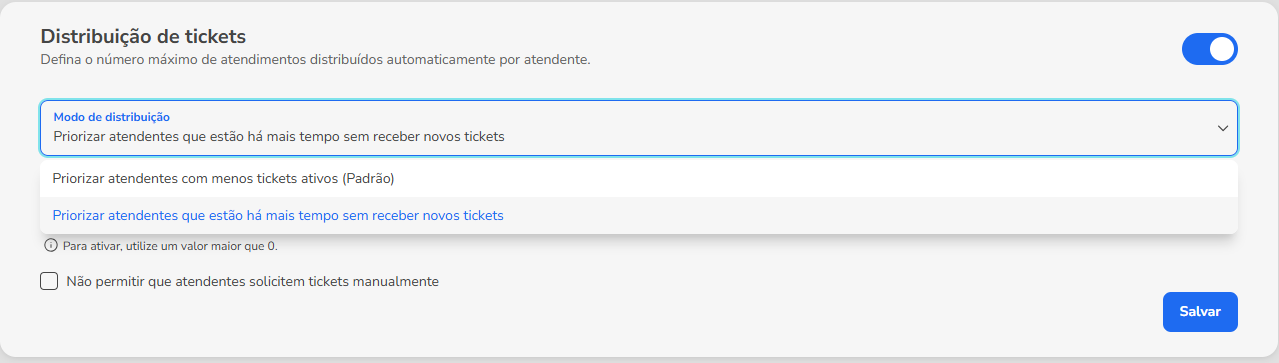
1. Modo padrão: round-robin baseado em carga de trabalho
- Tickets são distribuídos para o atendente com menos atendimentos ativos.
- Critério de desempate: quem está há mais tempo sem receber um novo ticket.
- Entenda como configurar a priorização de atendimento consultando nossa documentação sobre Priorização de Atendimento.
2. Modo alternativo: baseado em tempo de inatividade
- Prioriza atendentes que estão há mais tempo ociosos.
- Em caso de empate, usa a carga de tickets ativos como critério de desempate.
Ambos os modos são eficientes, mas exigem configuração consciente e adequada ao perfil da operação.
- Saiba mais sobre como gerenciar filas de atendimento no Blip, acessando nossa documentação sobre o gerenciamento de filas para direcionamento de tickets.
Onde tudo pode dar errado: as causas mais comuns das falhas
Causa 1: regras de roteamento mal configuradas
Este é, disparado, o erro mais comum. Quando as regras de roteamento estão mal estruturadas, o sistema pode:
- Não identificar para qual fila enviar o atendimento;
- Enviar o ticket para a fila Default;
- Atribuir o ticket a uma equipe sem atendente online.

- Consulte a documentação sobre como definir regras de atendimento no Blip Desk para garantir que seus tickets sejam direcionados corretamente.
Erros típicos de configuração:
- Uso incorreto de operadores: por exemplo, usar “é igual” quando deveria ser “contém”;
- Campos extras mal definidos ou inexistentes;
- Valores que não correspondem aos dados recebidos no fluxo;
- Múltiplas regras conflitantes ou sobrepostas.
Causa 2: ausência de vínculo entre atendentes e filas
Mesmo com regras bem configuradas, se os atendentes não estiverem atribuídos a uma fila, eles não receberão tickets. Isso é especialmente comum em operações que cadastram novos atendentes e esquecem de vinculá-los.
- Aprenda como atribuir um atendente na nossa documentação sobre como usar o Gerenciamento de filas para o direcionamento dos tickets de atendimento.
Causa 3: falha no motor de balanceamento (rara, mas possível)
Embora o Blip seja estável e confiável, falhas técnicas podem ocorrer. Se você já revisou todas as configurações e mesmo assim os tickets não estão sendo atribuídos, vale considerar um bug sistêmico.
Neste caso, é importante:
- Coletar evidências (print de fila com atendentes online e tickets parados);
- Relatar ao suporte com horário e IDs dos tickets.
Como evitar falhas com práticas inteligentes de configuração
Padronize suas regras de roteamento
Use nomes padronizados, condições claras e evite lógica complexa demais. Aqui está uma estrutura sugerida:
- Fonte: contact.extras.TipoUsuario
- Operador: “é igual”
- Valor esperado: “Aluno”
- Equipe destino: “Atendimento-Alunos”
Configure a fila Default como fallback
Garanta que a fila Default:
- Esteja ativa;
- Tenha ao menos um atendente online;
- Tenha regras de prioridade baixa, para evitar centralização excessiva.
Valide todas as atribuições de atendentes
Cada atendente deve estar:
- Online;
- Com slots livres;
- Vinculado à fila de destino.
Boas práticas para usar campos extras e tags
- No fluxo, armazene informações como cidade, tipo de usuário ou necessidade em contact.extras;
- Use tags para facilitar a segmentação e priorização posterior.
Usando dados a seu favor: dashboards e SLAs que fazem a diferença
Não se gerencia o que não se mede. Para manter a eficiência da operação, é essencial acompanhar indicadores de performance em tempo real.
🔎 Métricas críticas para monitorar:
- Tempo médio até atribuição do primeiro atendimento;
- Percentual de tickets atribuídos em menos de X segundos;
- Quantidade de tickets sem atribuição com atendente disponível;
- Filas com maior tempo de espera por atendimento.
- Saiba mais sobre como monitorar seu atendimento usando dashboards no Blip na nossa documentação de Monitoramento de Atendimento.
Como montar um dashboard eficaz:
- Use os dados do Blip Desk ou ferramentas externas como Power BI;
Crie alertas para:
- Tickets parados por mais de 2 minutos;
- Atendente com carga acima de 80% da capacidade;
- Fila sem atribuição em horário de pico.
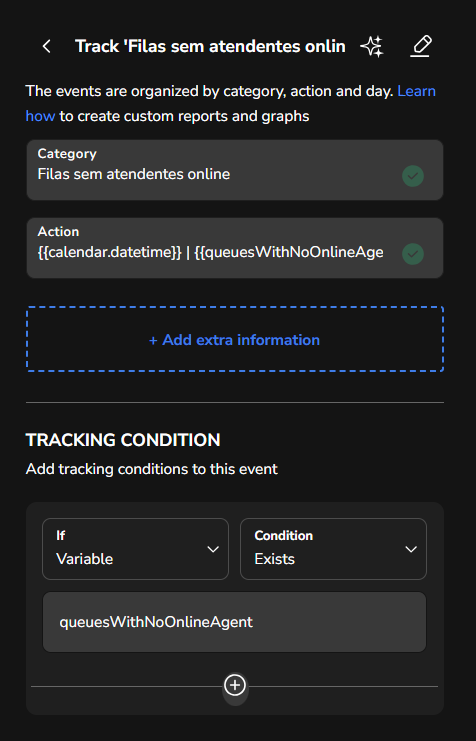
Como criar alertas e health checks operacionais
A prevenção de falhas pode ser automatizada. Este exemplo mostra como criar um health check simples para verificar filas sem atendentes online. Com o retorno da requisição get online agents, utilize o seguinte script para receber como retorno um objeto com o nome das filas que não possuem atendentes online:
javascript
function run(result) {
result = JSON.parse(result);
let queuesWithNoOnlineAgent = [];
if (result.resource && result.resource.total >= 1) {
for (let i = 0; i < result.resource.total; i++) {
if (result.resource.items[i]['agentsOnline'] == 0) {
queuesWithNoOnlineAgent.push(result.resource.items[i]['name']);
}
}
}
// retorna string vazia caso não tenha nenhum item
return queuesWithNoOnlineAgent.length === 0 ? "" : queuesWithNoOnlineAgent;
}
Registre eventos, construa relatórios ou até envie essas informações por e-mail para facilitar a gestão de possíveis incidentes. Uma boa sugestão é incluir um registro de eventos que combine o retorno deste script com a variável {{calendar.datetime}}, permitindo verificar o horário em que a validação foi realizada.
Bônus: checklist prático para validação de sua configuração atual
| Item | Verificado? |
| Todas as regras de roteamento foram testadas com valores reais? | ☐ |
| Existe uma fila Default ativa com atendente disponível? | ☐ |
| Todos os atendentes estão vinculados corretamente a suas filas? | ☐ |
| O modo de distribuição está alinhado ao perfil da operação? | ☐ |
| Existem alertas configurados para tickets parados? | ☐ |
| Dashboard de SLA de atribuição está em uso? | ☐ |
| Existem filas sem atendentes disponíveis dentro do horário de atendimento? | ☐ |
